Architecture
The core of the simulator is composed of a discrete event-based engine that manages every activity carried out by the agents during their life-cycle using a priority event queue, ordered by time. The main building blocks of the simulator are the following:
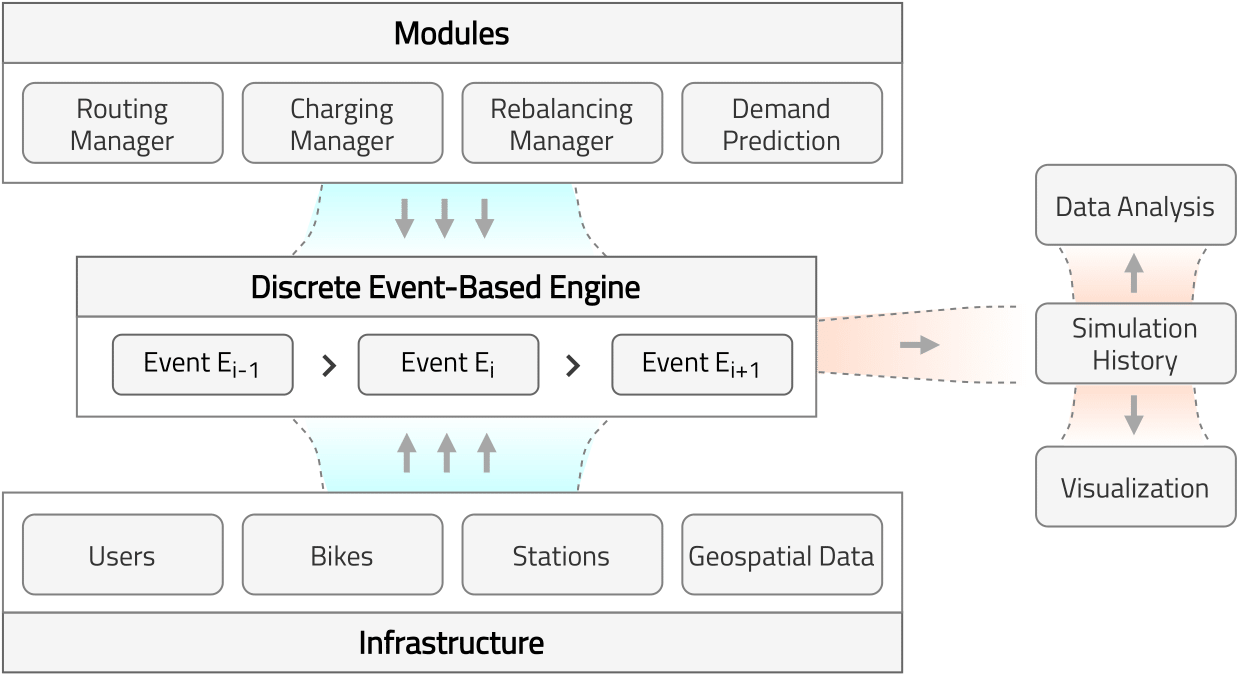
The event-based engine is at the core of the simulator and is fed by events produced by the agents. Any entity that can interact with or produce events is considered to be an agent. During the simulation execution, events are handled sequentially, in chronological order. Whenever any agent does an action or takes a decision, it generates and inserts new events into the priority queue.
Engine#
The simulator was implemented from scratch using Python 3.7.9. An object-oriented paradigm was adopted, where each agent is a class instance. The engine was developed on top of the SimPy 4.0.1 library [1], a process-based discrete-event simulation framework. Under this paradigm, processes are used to model the behavior of active components, such as bicycles and users. Processes live in an environment and interact with the environment and with each other via events . The most important event type for our application is the timeout , which allows a process to sleep for the given time, determining the duration of the activity. Events of this type are triggered after a certain amount of simulated time has passed.
Infrastructure#
The workflow of the simulator is described as follows: initially, Simpy's environment is created, and the provided infrastructure data is used to generate users, bikes, stations, and the road network. Users are introduced into the environment at a given location and departure time, and their task is to move to the specified target location using the defined mode of transportation. The location data is given in terms of longitude and latitude. The characteristics of the bike-sharing system are defined in the bikes module. If required, station data is also included in its corresponding module. Parameters for users, bikes, and stations are specified in their respective modules.
Geospatial data#
The geospatial information is provided by the geospatial data module, which contains a) the road graph, b) buildings data, and c) geospatial indexing system. Among these, only the road graph is strictly necessary to perform the simulation. Buildings data is optional, as it is used to generate users' origin and destination locations inside the buildings. This process yields realistic locations and avoids geographical obstacles such as highways or rivers. The geospatial indexing system is also optional, as it is used for the demand prediction and rebalancing manager, explained more in detail in Demand Prediction and Rebalancing.
Geospatial data was obtained using OpenStreetMap services. Given the bounding box of the city under study, OpenStreetMap highway tag is queried, downloaded, and converted into a directed and weighted graph, denoted as road network from this point onward.
User demand data#
The demand considered for the simulation is based on Bluebikes public bike-sharing system usage data. The user generation process takes advantage of this historical usage data and the buildings' spatial data. Buildings data is used to generate users' origin and destination locations inside the buildings. This process yields realistic locations and avoids geographical obstacles such as highways or rivers. The impact of variations in the demand was analyzed by repeating the simulations with a randomized distribution of the scattering of the origins and destinations in buildings within 300 m around stations.
Routing Manager#
The routing manager is in charge of choosing the most appropriate route (usually the shortest path) to transport people and vehicles around the urban space. This is a critical service and needs to be computed fast and with high resolution to yield results as close to reality. For the task of routing in road networks, an optimized fork fork of the Pandana Python library was implemented, as it uses contraction hierarchies (CH) to calculate super-fast travel accessibility metrics and shortest paths. The numerical code is in C++.
Contraction Hierarchies#
The contraction hierarchies algorithm is a speed-up technique for finding the shortest path in a graph, and it consists of two phases: preprocessing and query. To achieve its speed-up, CH relies on the fact that road networks do not change frequently. Given a directed, weighted graph with vertex set , edge set and cost function , the goal is to preprocess in such a way that the subsequent shortest path queries specified by a source node and a target node can be answered very quickly. In the preprocessing phase, is augmented by additional edges , which are shortcuts that represent the shortest paths in the original graph . In addition, a natural number is assigned to each node , called [2]. In the query phase, a bidirectional Dijkstra algorithm is applied on the augmented graph . Amongst all nodes settled from the Dijkstra, the one where the added distances from and to are minimal determines the shortest path from to . The query is highly efficient because the modified Dijkstra can discard the majority of the nodes and edges of while visiting only a small portion of the graph [2].
Additional modules#
The charging manager, the rebalancing manager, and the demand prediction modules will be discussed in greater depth under each mode of transportation.
References
[1] Matloff, N., 2008. Introduction to discrete-event simulation and the simpy language. Davis, CA. Dept of Computer Science. University of California at Davis. Retrieved on August, 2(2009), pp.1-33.
[2] Geisberger, R., Sanders, P., Schultes, D. and Delling, D., 2008, May. Contraction hierarchies: Faster and simpler hierarchical routing in road networks. In International Workshop on Experimental and Efficient Algorithms (pp. 319-333). Springer, Berlin, Heidelberg.